谷歌翻译在2006年首次推出时,只能翻译两种语言。到2016年,它支持超过103种语言,每天翻译超过1000亿字。现在,它不仅能翻译,还能实时转录8种使用最广泛的语言。机器在学习,而且学习速度很快。

神经机器翻译 (NMT)
NMT于2016年推出,是迄今为止最成功的机器翻译软件。它不仅吹嘘与前身机器翻译公司(SMT)相比,翻译错误减少了60%,而且翻译速度也快得多。
这些进步归功于系统的人工神经网络。据说,网络是基于人脑神经元模型,使系统能够在单词和短语之间建立重要的上下文联系。它可以建立这些联系,因为它受过学习语言规则的训练,通过从数据库中扫描数百万个句子的例子来识别共同特征。然后,机器使用这些规则制作统计模型,这有助于它学习如何构建句子。
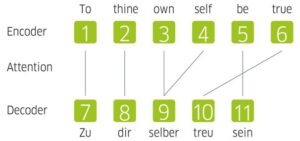
人工神经网络源语句进入网络,然后被发送到不同的隐藏网络“层”,最后以目标语言发送回。
人工语言
NMT的一个突破性特点是它利用了由数字组成的新的“共同语言 ” 。
以莎士比亚的《哈姆雷特》中的“要真实的自己”为例。首先,将短语的每个单词编码成数字(称为矢量):1、2、3、4、5、6。然后,这串数字进入神经网络,如左图所示。它在这里的隐藏层,在那里发生的魔法。系统根据其学习的语言规则,找出最适合的德语单词。产生数字7、8、9、10、11,与德语目标句中的单词相对应。然后将这些数字解码成目标语言:“Zu dir selber treu sein”。
本质上,系统将单词翻译成自己的语言,然后“思考”如何最好地根据它已经知道的内容 — — 很像人脑 — — 将它们变成可理解的句子。
理解内容
NMT可以成功地翻译文学作品,因为它开始分析上下文。它不仅关注自己想要翻译的单词,还关注前后出现的单词。
很像大脑破译信息片段,人工神经网络查看它被赋予的信息,并根据相邻单词生成下一个单词。随着时间的推移,它会根据前面的例子“学习”要关注哪些单词,以及在哪里建立最佳上下文连接。这个过程是“深度学习”的一种形式,它使翻译系统能够随着时间的流逝不断学习和改进。在NMT中,破译上下文称为“对齐 ” , 发生在注意机制中,它位于机器系统的编码器和解码器之间。
对齐的过程。对齐发生在人工神经网络的注意力机制中,并致力于推断单词的上下文。
当然,机器并不是完美的。当翻译回英语时,这句话变成了“忠于自己”,并没有完全捕捉到莎士比亚在都铎王朝时期写作的语气或历史脉络。逐字逐句的字面翻译是“Sei deinem eigenen Selbst treu”,但在德语中,莎士比亚的话通常被人类翻译为“Sei dir selbst treu”。
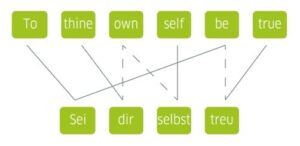
人工翻译:当由人翻译时,链接要比由机器翻译时复杂得多。这是因为对上下文的理解程度更高。
这里令人兴奋的是Google Translate如何领会“treu”一词在这方面的重要性。使用这个德语单词意味着Google Translate区分了“treu”和另一个德语单词“true ” , 前者的意思是“忠实于”一个人的真实本质,后者的意思是“真实”的东西在事实上是正确的。深度学习意味着一个翻译错误的短语很可能在几周后得到至少部分纠正。(也许这篇文章发表时,Google Translate 已经纠正了错误 ! )
这种与机器自身语言一起的不断改进意味着NMT可以被训练执行“零射击翻译”。这是一种将一种语言直接映射到另一种语言的能力,而不必使用英语作为中介。看来,对于机器和人类一样,熟能生巧。
迷失在翻译中
尽管机器翻译近年来取得了长足的进步,但仍未能达到可接受的文学标准。亨利·詹姆斯强调了理解原文的重要性,他说,理想的文学翻译必须是“不会失去任何东西”的人。至少从文学来看,机器离这个理想还有很长的路要走。
NMT 在文学翻译中继续苦苦挣扎于罕见的词汇、恰当的名词和高度技术性的语言,只有 25-30% 的产出被认为具有可接受的文学质量。关于将小说从德文翻译成英文的一篇英文研究报告(见文末参考资料:《使用神经机器翻译文学的挑战》)发现,虽然句法错误很少,但歧义词在翻译中仍然会丢失。然而,尽管存在这些错误,研究人员发现,机器翻译后的文本质量足够高,故事可以被理解,甚至让人愉快地阅读。 另一项关于将小说从英语翻译成加泰罗尼亚语的研究也取得了同样令人印象深刻的结果,因此平均有25%的母语人士认为质量与人类翻译者的质量相似: NMT 文学翻译无误率为 25% 。
然而,机器系统的性能并不等同于所有语言对。它特别与形态丰富的语言斗争,那里有很多屈折,如斯拉夫语言。当从不太复杂的语言翻译成更复杂的语言时,这一点尤其明显 — — 这意味着 NMT 还不能作为全局翻译工具使用。
寻找合适的声音
剩下的最大挑战是找到正确的语调和注册翻译文本。康涅狄格大学文学翻译项目主任彼得·康斯坦丁(Peter Constantine)说,机器要想在文学翻译中取得成功,就必须找到“合适的声音 ” 。
“那机器会模仿什么?”康斯坦丁问。“这是要做一些美丽和辉煌的异化,还是要进行惊人的归化,还是要让契诃夫听起来像他10分钟前在伦敦写作 ? ”
机器会选择哪种声音?以诺贝尔奖得主托马斯·曼的作品为例。他的写作风格随着时间的推移而改变,他早期的故事比后来的更重的小说更有趣。如果机器的翻译要传达预期的意思,就需要理解和捕捉这些变化。
必不可少的协作
显然,尽管机器尽了最大努力,但文学文本中人类语言的内在模糊性和灵活性仍然需要人类管理。NMT不能取代人类翻译,而是成为翻译文学作品的有用工具。
人类和机器翻译系统之间的协作是关键。这个问题的一个答案可能是后期编辑的机器翻译。在这里,熟悉机器翻译相关问题的专业翻译人员将编辑并更正机器初稿 — — 类似于老牌翻译人员如何帮助编辑缺乏经验的翻译人员的作品。轻度翻译后编辑由拼写和语法等细微编辑组成,而全面后编辑将有助于澄清句子结构和写作风格等更深层次的问题。当然,当涉及到翻译文学全后期编辑很可能需要生成正确语调的写作。研究人员将一部科幻小说从苏格兰盖尔语翻译成爱尔兰语,发现这种方法比从零开始翻译快31%(使用统计和神经机器翻译对小说进行后期编辑的工作量) 。而且,在从事后期编辑工作时,与从零开始翻译相比,译者的生产率提高了36 % , 每小时额外产生182个翻译单词。
随着人工智能在我们生活中扮演着越来越核心的角色,拥抱它作为翻译工具对于推动行业向前发展至关重要。机器翻译已经走过了如此漫长的道路,从它最初开始,并设定通过后期编辑技术辅助文学翻译 – 做累人的跑腿工作,使人类翻译可以做最后的修饰。它不仅减轻了翻译者的负担,而且为语言打开了多个机会之窗,从翻译以前从未翻译过的文本到为语言学习提供帮助。通过与 NMT 的合作,我们可以将其用作学习工具,为让所有人都能更方便地阅读文学和语言铺平道路。